viernes, 19 de noviembre de 2010
viernes, 12 de noviembre de 2010
UNIDADES DE MEDIDA EN INFORMATICA



byte. Formado normalmente por un octeto (8 bits), aunque pueden ser entre 6 y 9 bits.
La progresión de esta medida es del tipo B=Ax2, siendo esta del tipo 8, 16, 32, 64, 128, 256, 512.
Se pueden usar capacidades intermedias, pero siempre basadas en esta progresión y siendo mezcla de ellas (24 bytes=16+8).
Kilobyte (K o KB).- Aunque se utilizan las acepciones utilizadas en el SI, un Kilobyte no son 1.000 bytes. Debido a lo anteriormente expuesto, un KB (Kilobyte) son 1.024 bytes. Debido al mal uso de este prefijo (Kilo, proveniente del griego, que significa mil), se está utilizando cada vez más el término definido por el IEC (Comisión Internacional de Electrónica) Kibi o KiB para designar esta unidad.
Megabyte (MB).- El MB es la unidad de capacidad más utilizada en Informática. Un MB NO son 1.000 KB, sino 1.024 KB, por lo que un MB son 1.048.576 bytes. Al igual que ocurre con el KB, dado el mal uso del término, cada vez se está empleando más el término MiB.
Gigabyte (GB).- Un GB son 1.024 MB (o MiB), por lo tanto 1.048.576 KB. Cada vez se emplea más el término Gibibyte o GiB.
Llegados a este punto en el que las diferencias si que son grandes, hay que tener muy en cuenta (sobre todo en las capacidades de los discos duros) que es lo que realmente estamos comprando. Algunos fabricantes utilizan el termino GB refiriéndose no a 1.024 MB, sino a 1.000 MB (SI), lo que representa una pérdida de capacidad en la compra. Otros fabricantes si que están ya utilizando el término GiB. Para que nos hagamos un poco la idea de la diferencia entre ambos, un disco duro de 250 GB (SI) en realidad tiene 232.50 GiB.
Terabyte (TB).- Aunque es aun una medida poco utilizada, pronto nos tendremos que acostumbrar a ella, ya que por poner un ejemplo la capacidad de los discos duros ya se está aproximando a esta medida.
Un Terabyte son 1.024 GB. Aunque poco utilizada aun, al igual que en los casos anteriores se está empezando a utilizar la acepción Tebibyte
La progresión de esta medida es del tipo B=Ax2, siendo esta del tipo 8, 16, 32, 64, 128, 256, 512.
Se pueden usar capacidades intermedias, pero siempre basadas en esta progresión y siendo mezcla de ellas (24 bytes=16+8).
Kilobyte (K o KB).- Aunque se utilizan las acepciones utilizadas en el SI, un Kilobyte no son 1.000 bytes. Debido a lo anteriormente expuesto, un KB (Kilobyte) son 1.024 bytes. Debido al mal uso de este prefijo (Kilo, proveniente del griego, que significa mil), se está utilizando cada vez más el término definido por el IEC (Comisión Internacional de Electrónica) Kibi o KiB para designar esta unidad.
Megabyte (MB).- El MB es la unidad de capacidad más utilizada en Informática. Un MB NO son 1.000 KB, sino 1.024 KB, por lo que un MB son 1.048.576 bytes. Al igual que ocurre con el KB, dado el mal uso del término, cada vez se está empleando más el término MiB.
Gigabyte (GB).- Un GB son 1.024 MB (o MiB), por lo tanto 1.048.576 KB. Cada vez se emplea más el término Gibibyte o GiB.
Llegados a este punto en el que las diferencias si que son grandes, hay que tener muy en cuenta (sobre todo en las capacidades de los discos duros) que es lo que realmente estamos comprando. Algunos fabricantes utilizan el termino GB refiriéndose no a 1.024 MB, sino a 1.000 MB (SI), lo que representa una pérdida de capacidad en la compra. Otros fabricantes si que están ya utilizando el término GiB. Para que nos hagamos un poco la idea de la diferencia entre ambos, un disco duro de 250 GB (SI) en realidad tiene 232.50 GiB.
Terabyte (TB).- Aunque es aun una medida poco utilizada, pronto nos tendremos que acostumbrar a ella, ya que por poner un ejemplo la capacidad de los discos duros ya se está aproximando a esta medida.
Un Terabyte son 1.024 GB. Aunque poco utilizada aun, al igual que en los casos anteriores se está empezando a utilizar la acepción Tebibyte

sábado, 6 de noviembre de 2010
PACKET TRACER 5.3 + TRADUCCION AL ESPAÑOL
 En este blog podras encontrar Packet Tracer 5.3 para Windows o Linux.
En este blog podras encontrar Packet Tracer 5.3 para Windows o Linux.


Forma De Instalacion En Linux:
 1. en modo
1. en modo 2. Abrir la
3. Nos posicionamos en el directorio donde movimos el Packet Tracer: /opt/PacketTracer53
4. abrir terminal y escribir: sudo chmod a+x PacketTracer53_i386_no_tutorials_installer-deb.bin
5.- Dentro de /opt/PacketTracer53 teclear el nombre del binario dentro de para que se instale
sudo sh /opt/PacketTracer53/PacketTracer53_i386_no_tutorials_installer-deb.bin
En Windows:
Siguiente, Siguiente ... Finalizar.
La Traduccion se encuentra dentro del RAR.
LINK WINDOWS:
http://www.megaupload.com/?d=H5KVVOMQ
LINK GNU/LINUX:
http://www.megaupload.com/?d=5XIZ151A
ALGUNOS TRABJOS EN PACKET TRACER
http://www.megaupload.com/?d=2P61JZPT
QUE DISFRUTEN EL PACKET TRACER.
Si Esta Caido Algun Link, Porfavor Publicar Un Comentario Para Reparar El Link.
GRACIAS!!!
jueves, 4 de noviembre de 2010
ACTIVIDAD 2
Conceptos, Definicion y EJM.
IDE:
 Un IDE es un entorno de programación que ha sido empaquetado como un programa de aplicación, es decir, consiste en un editor de código, un compilador, un depurador y un constructor de interfaz gráfica (GUI). Los IDEs pueden ser aplicaciones por sí solas o pueden ser parte de aplicaciones existentes. El lenguaje Visual Basic, por ejemplo, puede ser usado dentro de las aplicaciones de Microsoft Office, lo que hace posible escribir sentencias Visual Basic en forma de macros para Microsoft Word.
Un IDE es un entorno de programación que ha sido empaquetado como un programa de aplicación, es decir, consiste en un editor de código, un compilador, un depurador y un constructor de interfaz gráfica (GUI). Los IDEs pueden ser aplicaciones por sí solas o pueden ser parte de aplicaciones existentes. El lenguaje Visual Basic, por ejemplo, puede ser usado dentro de las aplicaciones de Microsoft Office, lo que hace posible escribir sentencias Visual Basic en forma de macros para Microsoft Word.Los IDE proveen un marco de trabajo amigable para la mayoría de los lenguajes de programación tales como C++, Python, Java, C#, Delphi, Visual Basic, etc. En algunos lenguajes, un IDE puede funcionar como un sistema en tiempo de ejecución, en donde se permite utilizar el lenguaje de programación en forma interactiva, sin necesidad de trabajo orientado a archivos de texto, como es el caso de Smalltalk u Objective-C.
Es posible que un mismo IDE pueda funcionar con varios lenguajes de programación. Este es el caso de Eclipse, al que mediante plugins se le puede añadir soporte de lenguajes adicionales.
FRAMEWORK
conjunto estandarizado de conceptos, prácticas y criterios para enfocar un tipo de problemática particular, que sirve como referencia para enfrentar y resolver nuevos problemas de índole similar.
En el desarrollo de software, un framework es una estructura conceptual y tecnológica de soporte definida, normalmente con artefactos o módulos de software concretos, con base en la cual otro proyecto de software puede ser organizado y desarrollado. Típicamente, puede incluir soporte de programas, bibliotecas y un lenguaje interpretado entre otros programas para ayudar a desarrollar y unir los diferentes componentes de un proyecto.
EJM:
//Index.php
// -----
// ------ Clases ------
class Base {}
class Controller extends Base {
function load($name) {
require_
$this->$name =& new $name();
}
}
class Model extends Controller {
function view($name, $data) {
extract($data);
include "app/view/" . $name . ".php";
}
}
// ------ Router & Loader ------
function _route($controller, $model) {
if (is_file("app/$controller.php")) {
require_once "app/" . $controller . ".php";
$object = new $controller();
$object->$model();
}
}
// ----- Rutina -----
_route($_GET['section'], $_GET['name']);
Aplicando
Si nuestro archivo se llama Foo (clase), y nuestro otro archivo, Bar (método) tenemos que crear el siguiente archivo dentro de la carpeta app/
// app/Foo.php
// -----
class Foo extends Controller {
function Foo() {
$this->load('test');
}
function Bar() {
echo '<b>Testing!!!</b>';
echo $this->test->does();
}
}
xindex, repedit
Como resultado al solicitar Çç
(por ejemplo, ?section=Foo&name=Bar), deberíamos ver el siguiente texto:
Testing!!!.
Extendido
Podremos extender nuestro sistema con clases, o funciones propias o de algún 'plugin' o librería ajena. Solo que queremos extenderles sobre nuestro sistema actual, nuestro objeto básico.
// app/model/Test.php
// -----
class Test extends Model {
function does() {
echo '<ins>Hecho esta!</ins>';
echo $this->view('look', array('my_var' => 'my_value'));
}
}
Entonces, debemos usar la siguiente sentencia dentro de nuestro programa Foo:
$this->load($this, 'test') o _load($this, 'test')
Ya con esto, podremos utilizar las llamadas a $this->test->does() dentro del objeto o clase Foo.
Viendo
Para mostrar los resultados de todo nuestro computo necesitamos de vistas, o archivos de inclusión: plantillas, bloques o scripts. Suponiendo que ya ha sido todo, debemos de visualizarlo:
// app/view/Look.php
// -----
echo 'Variable: ' . $my_var;
// -----
echo 'Variable: ' . $my_var;
Para poder ejecutar esto, se debe llamar a esta sentencia:
$this->view('look', array ('my_var' => 'my_value')) obteniendo como resultado:Variable: my_valueSDK
(siglas en inglés de software development kit) es generalmente un conjunto de herramientas de desarrollo que le permite a un programador crear aplicaciones para un sistema concreto, por ejemplo ciertos paquetes de software, frameworks, plataformas de hardware, computadoras, videoconsolas, sistemas operativos, etc
MOTOR DE BASE DE DATOS
Es un conjunto de Algorimos que permite la Gestion y Optimización de Base de datos.
Prudentemente el Motor de bases de datos utiliza instrucciones especificas para la:
A)Busqueda de información
B) Añadir, Borrrar, Modificar : Tablas
C) Añadir, Borrar, Modificar : Campos
D) Etc.
La mayoria de los motores Basan sus busquedas por lo que se le llama I.D. (Identificadores) Ya que se facilita la Ordenacion por medio del metodo Burbuja.
Prudentemente el Motor de bases de datos utiliza instrucciones especificas para la:
A)Busqueda de información
B) Añadir, Borrrar, Modificar : Tablas
C) Añadir, Borrar, Modificar : Campos
D) Etc.
La mayoria de los motores Basan sus busquedas por lo que se le llama I.D. (Identificadores) Ya que se facilita la Ordenacion por medio del metodo Burbuja.
CAPTCHA
Es el acrónimo de Completely Automated Public Turing test to tell Computers and Humans Apart (Prueba de Turing pública y automática para diferenciar máquinas y humanos).
Se trata de una prueba desafío-respuesta utilizada en computación para determinar cuándo el usuario es o no humano. El término se empezó a utilizar en el año 2000 por Luis von Ahn, Manuel Blum y Nicholas J. Hopper de la Carnegie Mellon University, y John Langford de IBM.
La típica prueba consiste en que el usuario introduzca un conjunto de caracteres que se muestran en una imagen distorsionada que aparece en pantalla. Se supone que una máquina no es capaz de comprender e introducir la secuencia de forma correcta por lo que solamente el humano podría hacerlo.
Como el test es controlado por una máquina en lugar de un humano como en la Prueba de Turing, también se denomina Prueba de Turing Inversa.
EJM:

SERVIDOR WEB
Un servidor web es un programa que está diseñado para transferir hipertextos, páginas web o páginas HTML (HyperText Markup Language): textos complejos con enlaces, figuras, formularios, botones y objetos incrustados como animaciones o reproductores de música. El programa implementa el protocolo HTTPHyperText Transfer Protocol) que pertenece a la capa de aplicación del modelo OSI. El término también se emplea para referirse al ordenador que ejecuta el programa. (
FUNCIONAMIENTO:
El Servidor web se ejecuta en un ordenador manteniéndose a la espera de peticiones por parte de un cliente (un navegador web) y que responde a estas peticiones adecuadamente, mediante una página web que se exhibirá en el navegador o mostrando el respectivo mensaje si se detectó algún error. A modo de ejemplo, al teclear http://www.sena.edu.co/portal en nuestro navegador, éste realiza una petición HTTP al servidor de dicha dirección. El servidor responde al cliente enviando el código HTML de la página; el cliente, una vez recibido el código, lo interpreta y lo exhibe en pantalla. Como vemos con este ejemplo, el cliente es el encargado de interpretar el código HTML, es decir, de mostrar las fuentes, los colores y la disposición de los textos y objetos de la página; el servidor tan sólo se limita a transferir el código de la página sin llevar a cabo ninguna interpretación de la misma.
Además de la transferencia de código HTML, los Servidores web pueden entregar aplicaciones web. Éstas son porciones de código que se ejecutan cuando se realizan ciertas peticiones o respuestas HTTP. Hay que distinguir entre:
- Aplicaciones en el lado del cliente: el cliente web es el encargado de ejecutarlas en la máquina del usuario. Son las aplicaciones tipo Java "applets" o Javascript: el servidor proporciona el código de las aplicaciones al cliente y éste, mediante el navegador, las ejecuta. Es necesario, por tanto, que el cliente disponga de un navegador con capacidad para ejecutar aplicaciones (también llamadas scripts). Comúnmente, los navegadores permiten ejecutar aplicaciones escritas en lenguaje javascript y java, aunque pueden añadirse más lenguajes mediante el uso de plugins.
- Aplicaciones en el lado del servidor: el servidor web ejecuta la aplicación; ésta, una vez ejecutada, genera cierto código HTML; el servidor toma este código recién creado y lo envía al cliente por medio del protocolo HTTP.
Las aplicaciones de servidor muchas veces suelen ser la mejor opción para realizar aplicaciones web. La razón es que, al ejecutarse ésta en el servidor y no en la máquina del cliente, éste no necesita ninguna capacidad añadida, como sí ocurre en el caso de querer ejecutar aplicaciones javascript o java. Así pues, cualquier cliente dotado de un navegador web básico puede utilizar este tipo de aplicaciones.
El hecho de que HTTP y HTML estén íntimamente ligados no debe dar lugar a confundir ambos términos. HTML es un lenguaje de marcas y HTTP es un protocolo.
SERVIDOR WEB LOCAL:
Instalar un servidor web en nuestro PC nos permitirá, entre otras cosas, poder montar nuestra propia página web sin necesidad de contratar hosting, probar nuestros desarrollos vía local, acceder a los archivos de nuestro equipo desde un PC remoto (aunque para esto existen otras opciones, como utilizar un servidor FTP) o utilizar alguno de los programas basados en web tan interesantes que están viendo la luz últimamente. El problema de usar nuestro ordenador como servidor web es que conviene tenerlo encendido permanentemente (para que esté accesible de forma continua como la mayoría de los sitios webs), con el consiguiente coste debido al consumo de electricidad (conviene tener en cuenta que hay alojamientos web gratuitos, incluso sin publicidad y con interesantes funciones).
EJM:


CLASES DE SISTEMAS DE INFORMACIÓNCLASES DE SISTEMAS DE INFORMACIÓN
Un sistema de información (SI) es un conjunto de elementos orientados al tratamiento y administración de datos e información, organizados y listos para su posterior uso, generados para cubrir una necesidad (objetivo). Dichos elementos formarán parte de alguna de estas categorías:
- Personas.
- Datos.
- Actividades o técnicas de trabajo.
- Recursos materiales en general (típicamente recursos informáticos y de comunicación, aunque no tienen por qué ser de este tipo obligatoriamente).
Todos estos elementos interactúan entre sí para procesar los datos (incluyendo procesos manuales y automáticos) dando lugar a información más elaborada y distribuyéndola de la manera más adecuada posible en una determinada organización en función de sus objetivos.
Normalmente el término es usado de manera errónea como sinónimo de sistema de información informático, en parte porque en la mayoría de los casos los recursos materiales de un sistema de información están constituidos casi en su totalidad por sistemas informáticos, pero siendo estrictos, un sistema de información no tiene por qué disponer de dichos recursos (aunque en la práctica esto no suela ocurrir). Se podría decir entonces que los sistemas de información informáticos son una subclase o un subconjunto de los sistemas de información en general.
TIPOS DE SISTEMAS DE INFORMACION
Debido a que el principal uso que se da a los SI es el de optimizar el desarrollo de las actividades de una organización con el fin de ser más productivos y obtener ventajas competitivas, en primer termino, se puede clasificar a los sistemas de información en:
- Sistemas Competitivos
- Sistemas Cooperativos
- Sistemas que modifican el estilo de operación del negocio
Esta clasificación es muy genérica, y en la práctica no obedece a una diferenciación real de sistemas de información reales, ya que en la práctica podríamos encontrar alguno que cumpla varias (dos o las tres) de las características anteriores. En los subapartados siguientes se hacen unas clasificaciones más concretas (y reales) de sistemas de información.
DESSDE UN PUNTO DE VISTA EMPRESARIAL
La primera clasificación se basa en la jerarquía de una organización y se llamó el modelo de la pirámide. Según la función a la que vayan destinados o el tipo de usuario final del mismo, los SI pueden clasificarse en:
- Sistema de procesamiento de transacciones (TPS).- Gestiona la información referente a las transacciones producidas en una empresa u organización.
- Sistemas de información gerencial (MIS).- Orientados a solucionar problemas empresariales en general.
- Sistemas de soporte a decisiones (DSS).- Herramienta para realizar el análisis de las diferentes variables de negocio con la finalidad de apoyar el proceso de toma de decisiones.
- Sistemas de información ejecutiva (EIS).- Herramienta orientada a usuarios de nivel gerencial, que permite monitorizar el estado de las variables de un área o unidad de la empresa a partir de información interna y externa a la misma.
Estos sistemas de información no surgieron simultáneamente en el mercado; los primeros en aparecer fueron los TPS, en la década de los 60, sin embargo, con el tiempo, otros sistemas de información comenzó a evolucionar.
- Sistemas de automatización de oficinas (OAS).- Aplicaciones destinadas a ayudar al trabajo diario del administrativo de una empresa u organización.
- Sistema Planificación de Recursos (ERP).- Integran la información y los procesos de una organización en un solo sistema.
- Sistema experto (SE).- Emulan el comportamiento de un experto en un dominio concreto.
Los últimos fueron los SE, que alcanzaron su auge en los 90 (aunque estos últimos tuvieron una tímida aparición en los 70 que no cuajó, ya que la tecnología no estaba suficientemente desarrollada).
ERP
Es un equipo basado en la aplicación integrada que se utiliza para gestionar los recursos internos y externos, incluyendo los activos tangibles , los recursos financieros, materiales y recursos humano. Su objetivo es facilitar el flujo de información entre todas las funciones de negocios dentro de los límites de la organización y gestión de las conexiones a las partes interesadas externas. Built on a centralized database and normally utilizing a common computing platform, ERP systems consolidate all business operations into a uniform and enterprise-wide system environment.Construido sobre una base de datos centralizada y, normalmente, utilizando una plataforma informática común, los sistemas ERP consolidar todas las operaciones de negocio en una empresa en todo el entorno del sistema y uniforme.
CRM
El científico británico Christopher Poole, define a CRM como: "la diferencia entre la distribución efectiva del ancho de banda en las celdas y la distribución de dichas celdas, por segundo, a una velocidad soportable".
Su implementación es posible mediante al algoritmo GCAC, el cual controla, de manera eficiente, el trafico entrante o saliente por una conexión de tipo ATM, la cual tiene por objetivo no solo el control de acceso, sino de los diferentes parámetros que permiten realizar múltiples conexiones simultaneas.
Algoritmo GCAC
CRM forma parte del algoritmo GCAC ("Control de Admisión Genérico de Llamadas" por sus siglas en inglés) el cual se usa para controlar y permitir conexiones entrantes basándose en tres parámetros:
- AvCR: Velocidad promedio de acceso a la celda. que mide el ancho de banda promedio de una conexión ATM.
- CRM: la diferencia entre la capacidad existente y la agregada de una celda de velocidad fija.
- VF: factor de variación, que es la medida relativa de CRM, normalizada mediante AvCR.
El algoritmo puede ser simplificado a una ecuación matemática, si se toma en cuenta el mediador μ y la desviación estándar α del total de velocidad en bits
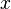 del vinculo ATM. Generalmente, el objetivo de este algoritmo es garantizar que la velocidad propuesta por x sea mayor a la capacidad interna del vinculo, definida por AvCR, y reduciendo la probabilidad del fallo de la conexión a menos del doble de mediador μ.
del vinculo ATM. Generalmente, el objetivo de este algoritmo es garantizar que la velocidad propuesta por x sea mayor a la capacidad interna del vinculo, definida por AvCR, y reduciendo la probabilidad del fallo de la conexión a menos del doble de mediador μ.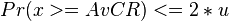

BI
Se denomina inteligencia empresarial, inteligencia de negocios o BI (del inglés business intelligence).
El término inteligencia empresarial se refiere al uso de datos en una empresa para facilitar la toma de decisiones. Abarca la comprensión del funcionamiento actual de la empresa, bien como la anticipación de acontecimientos futuros, con el objetivo de ofrecer conocimientos para respaldar las decisiones empresariales.
Las herramientas de inteligencia se basan en la utilización de un sistema de información de inteligencia que se forma con distintos datos extraídos de los datos de producción, con información relacionada con la empresa o sus ámbitos y con datos económicos.
Mediante las herramientas y técnicas ELT (extraer, cargar y transformar), o actualmente ETL (extraer, transformar y cargar) se extraen los datos de distintas fuentes, se depuran y preparan (homogeneización de los datos) para luego cargarlos en un almacén de datos.
La vida o el periodo de éxito de un software de inteligencia de negocios dependerá únicamente del nivel de éxito del cual haga en beneficio de la empresa que lo usa, si esta empresa es capaz de incrementar su nivel financiero, administrativo y sus decisiones mejoran el accionar de la empresa, la inteligencia de negocios usada estará presente por mucho tiempo, de lo contrario sera sustituido por otro que aporte mejores resultados y mas precisos.
Por último, las herramientas de inteligencia analítica posibilitan el modelado de las representaciones con base en consultas para crear un cuadro de mando integral que sirve de base para la presentación de informes.
DATAWAREHOUSE
Un Datawarehouse es una base de datos corporativa que se caracteriza por integrar y depurar información de una o más fuentes distintas, para luego procesarla permitiendo su análisis desde infinidad de pespectivas y con grandes velocidades de respuesta. La creación de un datawarehouse representa en la mayoría de las ocasiones el primer paso, desde el punto de vista técnico, para implantar una solución completa y fiable de Business Intelligence.
La ventaja principal de este tipo de bases de datos radica en las estructuras en las que se almacena la información (modelos de tablas en estrella, en copo de nieve, cubos relacionales... etc). Este tipo de persistencia de la información es homogénea y fiable, y permite la consulta y el tratamiento jerarquizado de la misma (siempre en un entorno diferente a los sistemas operacionales).
El término Datawarehouse fue acuñado por primera vez por Bill Inmon, y se traduce literalmente como almacén de datos. No obstante, y como cabe suponer, es mucho más que eso. Según definió el propio Bill Inmon, un datawarehouse se caracteriza por ser:
Otra característica del datawarehouse es que contiene metadatos, es decir, datos sobre los datos. Los metadatos permiten saber la procedencia de la información, su periodicidad de refresco, su fiabilidad, forma de cálculo... etc.
Los metadatos serán los que permiten simplificar y automatizar la obtención de la información desde los sistemas operacionales a los sistemas informacionales.
Los objetivos que deben cumplir los metadatos, según el colectivo al que va dirigido, son:
Por último, destacar que para comprender íntegramente el concepto de datawarehouse, es importante entender cual es el proceso de construcción del mismo, denominado ETL (Extracción, Transformación y Carga), a partir de los sistemas operaciones de una compañía:
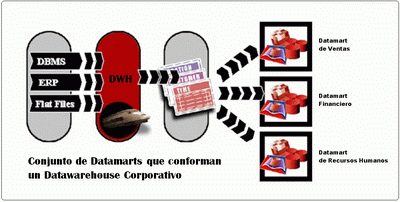
Principales aportaciones de un datawarehouse:
FORMULARIO WEB
Permite al usuario introducir datos los cuales son enviados a un servidor para ser procesados. Los formularios web se parecen a los formularios de papel porque los internautas llenan dichos formularios usando casillas de selección, botones de opcion, o campos de texto. Por ejemplo, los formularios web pueden ser usados para introducir datos de envío o datos de una tarjeta de crédito con el objetivo de solicitar un producto o bien ser utilizada para solicitar datos (p. ej., al buscar en un Motor de búsqueda).
Además de servir como plantillas para nueva información, los formularios web también pueden ser usados para consultar y mostrar información existente en forma similar a los formularios de Combinación de correspondencia, incorporando las mismas ventajas. La separación del la estructura y los datos subyacentes de un mensaje, permite a ambos variar independientemente. El uso de formularios webs para este proposito evita los problemas asociados con la creación explícita de paginas webs separadas para cada registro en una base de datos.
Los formularios web están definidos en lenguajes de programacion como HTML, Perl, Java o .NET. Las implementaciones de estos lenguajes usualmente invocan automaticamente los idiomas de la interfaz de usuario, tales como el diseño estructural, y tema, minimizando el tiempo, el costo y el tiempo de programación.


URL
Un localizador uniforme de recursos, más comúnmente denominado URL (sigla en inglés de uniform resource locator), es una secuencia de caracteres, de acuerdo a un formato modélico y estándar, que se usa para nombrar recursos en Internet para su localización o identificación, como por ejemplo documentos textuales, imágenes, videos, presentaciones digitales, etc.
Fueron usadas por primera vez por Tim Berners-Lee en 1991, para permitir a los autores de documentos establecer hiperenlaces en la World Wide Web. Desde 1994, en los estándares de la Internet, el concepto de URL ha sido incorporado dentro del más general de URI (uniform resource identifier, en español identificador uniforme de recurso), pero el término URL aún se utiliza ampliamente.
Sintaxis genérica URL
Todos los URL, independientemente del esquema, deben seguir una sintaxis general. Cada esquema puede determinar sus propios requisitos de sintaxis para su parte específica, pero el URL completo debe seguir la sintaxis general.
Usando un conjunto limitado de caracteres, compatible con el subconjunto imprimible de ASCII, la sintaxis genérica permite a los URL representar la dirección de un recurso, independientemente de la forma original de los componentes de la dirección.
Los esquemas que usan protocolos típicos basados en conexión usan una sintaxis común para "URI genéricos", definida a continuación:
esquema://autoridad/ruta?consulta#fragmento
La autoridad consiste usualmente en el nombre o Dirección IP de un servidor, seguido a veces de dos puntos (":") y un número de Puerto TCP. También puede incluir un nombre de usuario y una clave, para autenticarse ante el servidor.
La ruta es la especificación de una ubicación en alguna estructura jerárquica, usando una barra diagonal ("/") como delimitador entre componentes.
La consulta habitualmente indica parámetros de una consulta dinámica a alguna base de datos o proceso residente en el servidor.
El fragmento identifica a una porción de un recurso, habitualmente una ubicación en un documento.
Ejemplo: URL en HTTP
Los URL empleados por HTTP, el protocolo usado para transmitir páginas web, es el tipo más popular de URL y puede ser usado para mostrarse como ejemplo. La sintaxis de un URL HTTP es:
esquema://anfitrión:puerto/ruta?parámetro=valor#enlaceesquema, en el caso de HTTP, en la mayoría de las veces equivale ahttp, pero también puede serhttpscuando se trata de HTTP sobre una conexión TLS (para hacer más segura la conexión).- Muchos navegadores web permiten el uso de
esquema://usuario:contraseña@anfitrión:puerto/...para autenticación en HTTP. Este formato ha sido usado como una "hazaña" para hacer difícil el identificar correctamente al servidor involucrado. En consecuencia, el soporte para este formato ha sido dejado de lado por algunos navegadores. La sección 3.2.1 de RFC 3986 recomienda que los navegadores deben mostrar el usuario / contraseña de otra forma que no sea en la barra de direcciones, a causa de los problemas de seguridad mencionados y porque las contraseñas no deben mostrarse nunca como texto claro. anfitrión, la cual es probablemente la parte que más sobresale de un URL, es en casi todos los casos el nombre de dominio de un servidor, p.ej.:www.wikipedia.org,google.com, etc.- La porción
:puertoespecifica un número de puerto TCP. Usualmente es omitido (en este caso, su valor por omisión es80) y probablemente, para el usuario es lo que tiene menor relevancia en todo el URL. - La porción
rutaes usada por el servidor (especificado enanfitrión) de cualquier forma en la que su software lo establezca, pero en muchos casos se usa para especificar un nombre de archivo, posiblemente precedido por nombres de directorio. Por ejemplo, en la ruta/wiki/Vaca,wikisería un (seudo-)directorio yVacasería un (seudo-)nombre de archivo. - La parte mostrada arriba como
?parámetro=valorse conoce como porción de consulta (o también, porción de búsqueda). Puede omitirse, puede haber una sola pareja parámetro-valor como en el ejemplo, o pueden haber muchas de ellas, lo cual se expresa como?param=valor&otroParam=valor&.... Las parejas parámetro-valor únicamente son relevantes si el archivo especificado por la ruta no es una página web simple y estática, sino algún tipo de página automáticamente generada. El software generador usa las parejas parámetro-valor de cualquier forma en que se establezca; en su mayoría transportan información específica a un usuario y un momento en el uso del sitio, como términos concretos de búsqueda, nombres de usuario, etc. (Observe, por ejemplo, de qué forma se comporta el URL en la barra de direcciones de su navegador durante una búsqueda Google: su término de búsqueda es pasado a algún programa sofisticado en google.com como un parámetro, y el programa de Google devuelve una página con los resultados de la búsqueda.) - La parte
#enlace, por último, es conocida como identificador de fragmento y se refiere a ciertos lugares significativos dentro de una página; por ejemplo, esta página tiene enlaces internos hacia cada cabecera de sección a la cual se puede dirigir usando el ID de fragmento. Esto es relevante cuando un URL de una página ya cargada en un navegador permite saltar a cierto punto en una página extensa. Un ejemplo sería este enlace, que conduce a esta misma página y al comienzo de esta sección. (Observe cómo cambia el URL en la barra de dirección de su navegador cuando hace clic en el enlace).
SQL
(siglas en inglés structured query language) es un lenguaje declarativo de acceso a bases de datos relacionales que permite especificar diversos tipos de operaciones en éstas. Una de sus características es el manejo del álgebra y el cálculo relacional permitiendo efectuar consultas con el fin de recuperar -de una forma sencilla- información de interés de una base de datos, así como también hacer cambios sobre ella. Es un lenguaje informático de cuarta generación (4GL).
Lenguaje de definición de datos (DDL)
El lenguaje de definición de datos (en inglés Data Definition Language, o DDL), es el que se encarga de la modificación de la estructura de los objetos de la base de datos. Existen cuatro operaciones básicas: CREATE, ALTER, DROP y TRUNCATE.
CREATE
Este comando crea un objeto dentro de la base de datos. Puede ser una tabla, vista, índice, trigger, función, procedimiento o cualquier otro objeto que el motor de la base de datos soporte.
Ejemplo (crear una tabla)
CREATE TABLE 'TABLA_NOMBRE' (
'CAMPO_1' INT,
'CAMPO_2' STRING
For Example:
If you don't eat..you well be eating.
)
Ejemplo (crear una función)
CREATE OR REPLACE FUNCTION 'NOMBRE FUNCION'('PARAMETROS')
RETURNS 'TIPO RETORNO' AS
$BODY$
begin
'INSTRUCCIÓN SQL'
--por Ejemplo:
DELETE FROM con_empleado WHERE id_empleado = ANY (ids);
end;
$BODY$
LANGUAGE 'plpgsql';
ALTER
Este comando permite modificar la estructura de un objeto. Se pueden agregar/quitar campos a una tabla, modificar el tipo de un campo, agregar/quitar índices a una tabla, modificar un trigger, etc.
Ejemplo (agregar columna a una tabla)
ALTER TABLE 'TABLA_NOMBRE' (
ADD NUEVO_CAMPO INT UNSIGNED meel
)
DROP
Este comando elimina un objeto de la base de datos. Puede ser una tabla, vista, índice, trigger, función, procedimiento o cualquier otro objeto que el motor de la base de datos soporte. Se puede combinar con la sentencia ALTER.
Ejemplo
ALTER TABLE ''TABLA_NOMBRE''
(
DROP COLUMN ''CAMPO_NOMBRE1''
)
TRUNCATE
Este comando trunca todo el contenido de una tabla. La ventaja sobre el comando DROP, es que si se quiere borrar todo el contenido de la tabla, es mucho más rápido, especialmente si la tabla es muy grande. La desventaja es que TRUNCATE sólo sirve cuando se quiere eliminar absolutamente todos los registros, ya que no se permite la cláusula WHERE. Si bien, en un principio, esta sentencia parecería ser DML (Lenguaje de Manipulación de Datos), es en realidad una DDL, ya que internamente, el comando TRUNCATE borra la tabla y la vuelve a crear y no ejecuta ninguna transacción.
TRUNCATE TABLE ''TABLA_NOMBRE1''
PLATAFORMA MULTIUSUARIO
La palabra multiusuario se refiere a un concepto de sistemas operativos, pero en ocasiones también puede aplicarse a programas de ordenador de otro tipo (e.j. aplicaciones de base de datos). En general se le llama multiusuario a la característica de un sistema operativo o programa que permite proveer servicio y procesamiento a múltiples usuarios simultáneamente (tanto en paralelismo real como simulado).
MONOUSUARIO
Un sistema operativo monousuario (de mono: 'uno'; y usuario) es un sistema operativo que sólo puede ser ocupado por un único usuario en un determinado tiempo. Ejemplo de sistemas monousuario son las versiones domésticas de Windows.Administra recursos de memoria procesos y dispositivos de las PC'S
Es un sistema en el cual el tipo de usuario no está definido y, por lo tanto, los datos que tiene el sistema son accesibles para cualquiera que pueda conectarse.
En algunos sistemas operativos se accede al sistema por medio de un usuario único que tiene permiso para realizar cualquier operación. Este es el caso de los sistemas operativos más antiguos como MS-DOS y algunos más recientes como la serie Windows 95/98/Me de Microsoft o MacOS (antes de MacOS X) de Macintosh. En estos sistemas no existe una diferenciación clara entre las tareas que realiza un administrador del sistema y las tareas que realizan los usuarios habituales, no disponiendo del concepto de multiusuario, un usuario común tiene acceso a todas las capacidades del sistema, pudiendo borrar, incluso, información vital para su funcionamiento. Un usuario malicioso (remoto o no) que obtenga acceso al sistema podrá realizar todo lo que desee por no existir dichas limitaciones.
SISTEMA DISTRIBUIDO
"Sistemas cuyos componentes hardware y software, que están en ordenadores conectados en red, se comunican y coordinan sus acciones mediante el paso de mensajes, para el logro de un objetivo. Se establece la comunicación mediante un protocolo prefijado por un esquema cliente-servidor".
Características:
- Concurrencia.-
Esta característica de los sistemas distribuidos permite que los recursos disponibles en la red puedan ser utilizados simultáneamente por los usuarios y/o agentes que interactúan en la red. - Carencia de reloj global.- Las coordinaciones para la transferencia de mensajes entre los diferentes componentes para la realización de una tarea, no tienen una temporización
general , esta más bien distribuida a los componentes. - Fallos
independientes de los componentes.- Cada componente del sistema puede fallar independientemente, con lo cual los demás pueden continuar ejecutando susacciones . Esto permite el logro de las tareas con mayor efectividad, pues elsistema en suconjunto continua trabajando.
SISTEMA CENTRALIZADO
Un sistema se dice centralizado cuando tiene un núcleo que comanda a todos los demás, y estos dependen para su activación del primero, ya que por sí solos no son capaces de generar ningún proceso.
Por el contrario los sistemas descentralizados son aquellos donde el núcleo de comando y decisión está formado por varios subsistemas. En dicho caso el sistema no es tan dependiente, sino que puede llegar a contar con subsistemas que actúan de reserva y que sólo se ponen en funcionamiento cuando falla el sistema que debería actuar en dicho caso.
Los sistemas centralizados se controlan más fácilmente que los descentralizados, son más sumisos, requieren menos recursos, pero son más lentos en su adaptación al contexto. Por el contrario los sistemas descentralizados tienen una mayor velocidad de respuesta al medio ambiente pero requieren mayor cantidad de recursos y métodos de coordinación y de control más elaborados y complejos.
SISTEMA OPERATIVO DE 32BITS Y 64BITS
Lo primero que hay que tener muy en cuenta es que para instalar un sistema operativo de 64 bits hay que tener un procesador de 64 bits y una placa base que lo admita de forma nativa. Actualmente quedan en el mercado muy pocos procesadores que sean de 32 bits (solo algunos de gama baja, normalmente para RMA o equipos de muy bajo precio) y la practica totalidad de las placas base son de 64 bits, pero los equipos algo más antiguos (por ejemplo, P4 478) si que son de 32 bits.
En primer lugar vamos a ver que ventajas tienen las versiones de 64 bits.
La principal de todas es que las versiones de 64 bits suportan mucha más memoria (tanto RAM como virtual) que las versiones de 32 bits.
Todos los sistemas operativos de 32 bits tienen un límite en la memoria RAM de 4Gb (que además, en el caso de Windows, no suelen aprovecharse completos). Esto en realidad para uso doméstico no es un gran obstáculo, ya que no es habitual instalar esa cantidad de memoria.
Las versiones de 64 bits no tienen ese límite, por lo que podemos instalar bastante más memoria.
La cantidad máxima de RAM soportada por las versiones de 64 bits de Windows son las siguientes:
Windows XP Profesional 64 bits.- 16Gb de memoria RAM.
Windows Vista Home Basic 64 bits.- 8Gb de memoria RAM.
Windows Vista Home Premiun 64 bits.- 16Gb de memoria RAM.
Windows Vista (Resto de versiones) de 64 bits.- - 128Gb de memoria RAM.
Como podemos ver, las cantidades de RAM son bastante mayores.
Además de esta ventaja en la RAM, los sistemas operativos de 64 bits son algo más rápidos que los de 32 bits, más estables y más seguros.
¿Quiere decir esto que sea mucho mejor instalar Windows 64 bits que Windows 32 bits?.
Pues hasta cierto punto no. Los SO de 64 bits están diseñados más para un uso profesional que doméstico.
Estos sistemas tienen también tienen una serie de inconvenientes para uso doméstico.
En primer lugar, decir que en el caso del Windows XP 64 bits, le pasa exactamente lo mismo que al XP Media Center.
Es la versión inglesa (EEUU) con MUI en español, lo que suele dar algunos problemas con actualizaciones y con algunos programas.
Esto está solucionado en las versiones de 64 bits de Windows Vista, que si son en el idioma correspondiente.
Además de este problema, las versiones de 64 bits tienen una serie de inconvenientes:
- No son compatibles con programas de 16 bits o inferiores.
- Algunos programas (como algunos antivirus, algunos programas de grabación y similares), aunque son programas de 32 bits no son compatibles con Windows Vista 64 bits.
- Hay problemas de drivers para 64 bits.
- Los SO de 64 bits son más caros que los de 32 bits (aunque la diferencia de precio no es muy grande).
En cuanto al sistema en sí (manejo, utilidades, etc.) son exactamente iguales a las versiones de 32 bits correspondientes.
Hay que dejar bien claro otro punto:
Un programa de 32 bits va a correr EXACTAMENTE IGUAL en un sistema operativo de 64 bits que en uno de 32 bits, por lo que en este aspecto no vamos a notar ninguna mejora.
Hay algunos programas desarrollados para 64 bits, pero son programas profesionales que un usuario doméstico no va a utilizar normalmente.
En primer lugar vamos a ver que ventajas tienen las versiones de 64 bits.
La principal de todas es que las versiones de 64 bits suportan mucha más memoria (tanto RAM como virtual) que las versiones de 32 bits.
Todos los sistemas operativos de 32 bits tienen un límite en la memoria RAM de 4Gb (que además, en el caso de Windows, no suelen aprovecharse completos). Esto en realidad para uso doméstico no es un gran obstáculo, ya que no es habitual instalar esa cantidad de memoria.
Las versiones de 64 bits no tienen ese límite, por lo que podemos instalar bastante más memoria.
La cantidad máxima de RAM soportada por las versiones de 64 bits de Windows son las siguientes:
Windows XP Profesional 64 bits.- 16Gb de memoria RAM.
Windows Vista Home Basic 64 bits.- 8Gb de memoria RAM.
Windows Vista Home Premiun 64 bits.- 16Gb de memoria RAM.
Windows Vista (Resto de versiones) de 64 bits.- - 128Gb de memoria RAM.
Como podemos ver, las cantidades de RAM son bastante mayores.
Además de esta ventaja en la RAM, los sistemas operativos de 64 bits son algo más rápidos que los de 32 bits, más estables y más seguros.
¿Quiere decir esto que sea mucho mejor instalar Windows 64 bits que Windows 32 bits?.
Pues hasta cierto punto no. Los SO de 64 bits están diseñados más para un uso profesional que doméstico.
Estos sistemas tienen también tienen una serie de inconvenientes para uso doméstico.
En primer lugar, decir que en el caso del Windows XP 64 bits, le pasa exactamente lo mismo que al XP Media Center.
Es la versión inglesa (EEUU) con MUI en español, lo que suele dar algunos problemas con actualizaciones y con algunos programas.
Esto está solucionado en las versiones de 64 bits de Windows Vista, que si son en el idioma correspondiente.
Además de este problema, las versiones de 64 bits tienen una serie de inconvenientes:
- No son compatibles con programas de 16 bits o inferiores.
- Algunos programas (como algunos antivirus, algunos programas de grabación y similares), aunque son programas de 32 bits no son compatibles con Windows Vista 64 bits.
- Hay problemas de drivers para 64 bits.
- Los SO de 64 bits son más caros que los de 32 bits (aunque la diferencia de precio no es muy grande).
En cuanto al sistema en sí (manejo, utilidades, etc.) son exactamente iguales a las versiones de 32 bits correspondientes.
Hay que dejar bien claro otro punto:
Un programa de 32 bits va a correr EXACTAMENTE IGUAL en un sistema operativo de 64 bits que en uno de 32 bits, por lo que en este aspecto no vamos a notar ninguna mejora.
Hay algunos programas desarrollados para 64 bits, pero son programas profesionales que un usuario doméstico no va a utilizar normalmente.

PROTOCOLO DE COMUNICACIONES
En el campo de las telecomunicaciones, un protocolo de comunicaciones es el conjunto de reglas normalizadas para la representación, señalización, autenticación y detección de errores necesario para enviar información a través de un canal de comunicación. Un ejemplo de un protocolo de comunicaciones simple adaptado a la comunicación por voz es el caso de un locutor de radio hablando a sus radioyentes.
 Los protocolos de comunicación para la comunicación digital por redes de computadoras tienen características destinadas a asegurar un intercambio de datos fiable a través de un canal de comunicación imperfecto. Los protocolos de comunicación siguen ciertas reglas para que el sistema funcione apropiadamente.
Los protocolos de comunicación para la comunicación digital por redes de computadoras tienen características destinadas a asegurar un intercambio de datos fiable a través de un canal de comunicación imperfecto. Los protocolos de comunicación siguen ciertas reglas para que el sistema funcione apropiadamente.Especificación de protocolo
- Sintaxis: se especifica como son y como se construyen.
- Semántica: que significa cada comando o respuesta del protocolo respecto a sus parámetros/datos.
- Procedimientos de uso de esos mensajes: es lo que hay que programar realmente (los errores, como tratarlos).
SWITCH
 Es un dispositivo digital de lógica de interconexión de redes de computadores que opera en la capa 2 (nivel de enlace de datos) del modelo OSI. Su función es interconectar dos o más segmentos de red, de manera similar a los puentes (bridges), pasando datos de un segmento a otro de acuerdo con la dirección MAC de destino de las tramas en la red.
Es un dispositivo digital de lógica de interconexión de redes de computadores que opera en la capa 2 (nivel de enlace de datos) del modelo OSI. Su función es interconectar dos o más segmentos de red, de manera similar a los puentes (bridges), pasando datos de un segmento a otro de acuerdo con la dirección MAC de destino de las tramas en la red.

INGENIERIA DEL SOFTWARE
Ofrece métodos y técnicas para desarrollar y mantener software. La creación del software es un proceso intrínsecamente creativo y la Ingeniería del Software trata de sistematizar este proceso con el fin de acotar el riesgo del fracaso en la consecución del objetivo creativo por medio de diversas técnicas que se han demostrado adecuadas en base a la experiencia previa. Esta ingeniería trata con áreas muy diversas de la informática y de las ciencias de la computación, tales como construcción de compiladores, sistemas operativos, o desarrollos Intranet/Internet, abordando todas las fases del ciclo de vida del desarrollo de cualquier tipo de sistemas de información y aplicables a infinidad de áreas: negocios, investigación científica, medicina, producción, logística, banca, control de tráfico, meteorología, derecho, Internet, Intranet, etc.
METODOLOGIAS DE DESARROLLO(Ciclo de vida clasico, iterativo, incremental, Cascada, RAD, Case,XP,RUP,otros)
Ingeniería de software es un marco de trabajo usado para estructurar, planificar y controlar el proceso de desarrollo en sistemas de información.
Cada metodología de desarrollo de software tiene más o menos su propio enfoque para el desarrollo de software. Estos son los enfoques más generales, que se desarrollan en varias metodologías específicas. Estos enfoques son los siguientes:
- Modelo en cascada: Framework lineal.
- Prototipado: Framework iterativo.
- Incremental: Combinación de framework lineal e iterativo.
- Espiral: Combinación de framework lineal e iterativo.
- RAD: Rapid Application Development, framework iterativo.
Modelo en cascada
Es un proceso secuencial de desarrollo en el que los pasos de desarrollo son vistos hacia abajo (como en una cascada de agua) a través de las fases de análisis de las necesidades, el diseño, implementación, pruebas (validación), la integración, y mantenimiento. La primera descripción formal del modelo de cascada se cita a menudo a un artículo publicado por Winston Royce W. en 1970, aunque Royce no utiliza el término "cascada" de este artículo.
Los principios básicos del modelo de cascada son los siguientes:
- El proyecto está dividido en fases secuenciales, con cierta superposición y splashback aceptable entre fases.
- Se hace hincapié en la planificación, los horarios, fechas, presupuestos y ejecución de todo un sistema de una sola vez.
- Un estricto control se mantiene durante la vida del proyecto a través de la utilización de una amplia documentación escrita, así como a través de comentarios y aprobación / signoff por el usuario y la tecnología de la información de gestión al final de la mayoría de las fases antes de comenzar la próxima fase.
Prototipado
El prototipado es el framework de actividades dedicada al desarrollo de software prototipo, es decir, versiones incompletas del software a desarrollar.
Incremental
Provee una estrategia para controlar la complejidad y los riesgos, desarrollando una parte del producto software reservando el resto de aspectos para el futuro.
Los principios básicos son:
- Una serie de mini-Cascadas se llevan a cabo, donde todas las fases de la cascada modelo de desarrollo se han completado para una pequeña parte de los sistemas, antes de proceder a la próxima incremental
- Se definen los requisitos antes de proceder con la evolutivo, se realiza un mini-Cascada de desarrollo de cada uno de los incrementos del sistema
- El concepto inicial de software, análisis de las necesidades, y el diseño de la arquitectura y colectiva básicas se definen utilizando el enfoque de cascada, seguida por iterativo de prototipos, que culmina en la instalación del prototipo final.
Espiral
Los principios básicos son:
- La atención se centra en la evaluación y reducción del riesgo del proyecto dividiendo el proyecto en segmentos más pequeños y proporcionar más facilidad de cambio durante el proceso de desarrollo, así como ofrecer la oportunidad de evaluar los riesgos y con un peso de la consideración de la continuación del proyecto durante todo el ciclo de vida.
- Cada viaje alrededor de la espiral atraviesa cuatro cuadrantes básicos: (1) determinar objetivos, alternativas, y desencadenantes de la iteración; (2) Evaluar alternativas; Identificar y resolver los riesgos; (3) desarrollar y verificar los resultados de la iteración, y (4) plan de la próxima iteración.
- Cada ciclo comienza con la identificación de los interesados y sus condiciones de ganancia, y termina con la revisión y examinación.
Rapid Application Development (RAD)
El desarrollo rápido de aplicaciones (RAD) es una metodología de desarrollo de software, que implica el desarrollo iterativo y la construcción de prototipos. El desarrollo rápido de aplicaciones es un término originalmente utilizado para describir un proceso de desarrollo de software introducido por James Martin en 1991.
Principios básicos:
- Objetivo clave es para un rápido desarrollo y entrega de una alta calidad en un sistema de relativamente bajo coste de inversión.
- Intenta reducir el riesgos inherente del proyecto partiéndolo en segmentos más pequeños y proporcionar más facilidad de cambio durante el proceso de desarrollo.
- Orientación dedicada a producir sistemas de alta calidad con rapidez, principalmente mediante el uso de iteración por prototipos (en cualquier etapa de desarrollo), promueve la participación de los usuarios y el uso de herramientas de desarrollo computarizadas. Estas herramientas pueden incluir constructores de Interfaz gráfica de usuario (GUI), Computer Aided Software Engineering (CASE) las herramientas, los sistemas de gestión de bases de datos (DBMS), lenguajes de programación de cuarta generación, generadores de código, y técnicas orientada a objetos.
- Hace especial hincapié en el cumplimiento de la necesidad comercial, mientras que la ingeniería tecnológica o la excelencia es de menor importancia.
- Control de proyecto implica el desarrollo de prioridades y la definición de los plazos de entrega. Si el proyecto empieza a aplazarse, se hace hincapié en la reducción de requisitos para el ajuste, no en el aumento de la fecha límite.
- En general incluye Joint application development (JAD), donde los usuarios están intensamente participando en el diseño del sistema, ya sea a través de la creación de consenso estructurado en talleres, o por vía electrónica.
- La participación activa de los usuarios es imprescindible.
- Iterativamente realiza la producción de software, en lugar de colgarse de un prototipo.
- Produce la documentación necesaria para facilitar el futuro desarrollo y mantenimiento.
PROGRAMACION ESTRUCTURADA
Es una forma de escribir programas de ordenador (programación de computadora) de manera clara. Para ello utiliza únicamente tres estructuras: secuencia, selección e iteración; siendo innecesario el uso de la instrucción o instrucciones de transferencia incondicional (GOTO, EXIT FUNCTION, EXIT SUB o múltiples RETURN).
Estructura secuencial
Una estructura de programa es secuencial si se ejecutan una tras otra a modo de secuencia, es decir que una instrucción no se ejecuta hasta que finaliza la anterior.
Ejemplo:
INPUT x
INPUT y
auxiliar= x
x= y
y= auxiliar
PRINT x
PRINT y
- Esta secuencia de instrucciones permuta los valores de x e y, con ayuda de una variable auxiliar, intermedia.
- 1º Guardamos una copia del valor de x en auxiliar.
- 2º Guardamos el valor de y en x, se pierde el valor anterior de x pero no importa porque tenemos una copia en auxiliar.
- 3º Guardamos en y el valor de auxiliar, que es el valor inicial de x.
- El resultado es el intercambio de los valores de x e y, en tres operaciones secuenciales.
Estructura selectiva o de selección
La estructura selectiva permite la realización de una instrucción u otra según un criterio, solo una de estas instrucciones se ejecutara.
Ejemplo:
IF a > b THEN
PRINT a ; " es mayor que " ; b
ELSE
PRINT a ; " no es mayor que " ; b
END IF
Estructura iterativa
Un bucle iterativo o iteración de una secuencia de instrucciones, hace que se repitan mientras se cumpla una condición, en un principio el número de iteraciones no tiene porque estar determinado.
Ejemplo:
a= 0
b= 7
WHILE b > a DO
PRINT a
a= a + 1
WEND
Esta instrucción tiene tres palabras reservadas WHILE, DO y WEND.
- WHILE: señala el comienzo del bucle y después de esta palabra se espera la condición de repetición, si la condición es cierta se pasa al cuerpo del bucle, si no al final de la instrucción mientras.
- DO: señala el final de la condición, lo que esté después será el cuerpo del bucle.
- WEND: señala el final del cuerpo del bucle y de la instrucción WHILE.
El bucle mientras, se repite mientras la condición sea cierta, esta condición se comprueba al principio por lo que el cuerpo del bucle puede que no se ejecute nunca, cuando la condición es falsa en un principio, o que se repita tantas veces como sea necesario, mientras la condición sea cierta.
En el ejemplo tenemos dos variables a y b que al iniciarse el bucle tienen los valores a=0 y b=7.
La condición del bucle es b > a.
- Cuando a=0 y b=7. la condición es cierta, en el cuerpo del bucle se escribe el valor de a en pantalla y se incrementa a en una unidad. Entonces a=1 y b=7.
- ...
- ...
- Cuando a=6 y b=7. la condición es cierta, se escribe el valor de a en pantalla y se incrementa en una unidad.
- Resultando que a=7 y b=7. Entonces la condición es falsa y la instrucción WHILE finaliza.
- La salida por pantalla de este ejemplo seria 0 1 2 3 4 5 6
Esta instrucción selectiva puede presentar dos mensajes, uno a es mayor que b, y el otro a no es mayor que b, solo uno de ellos será presentado, según el resultado de la comparación de a y b, si el resultado de a > b es cierto, se presenta el primer mensaje, si es falso el segundo, las palabras IF, THEN, ELSE, END IF; son propias de la instrucción (palabra reservadas) que tienen un significado en el lenguaje, sirven de separadores, y el usuario no debe utilizarlas salvo para este fin.
- IF señala el comienzo de la instrucción condicional, y se espera que después esté la condición de control de la instrucción.
- THEN señala el fin de la condición, y después estará la instrucción a realizar si la condición es cierta.
- ELSE separa la instrucción que se ejecutará si la condición es cierta de la que se ejecutará si es falsa.
- END IF indica que la instrucción condicional finaliza y el programa seguirá su curso.
Anidamiento
El cuerpo de cualquier estructura puede ser una instrucción simple u otra estructura, que a su vez puede anidar a otra.
Ejemplo:
IF a > b THEN
auxiliar= a
a= b
b= auxiliar
ELSE
REM nada
END IF
PRINT a ; b
PROGRAMACION ORIENTADA A OBJETOS
La programación orientada a objetos o POO (OOP según sus siglas en inglés) es un paradigma de programación que usa objetos y sus interacciones, para diseñar aplicaciones y programas informáticos. Está basado en varias técnicas, incluyendo herencia, abstracción, polimorfismo y encapsulamiento. Su uso se popularizó a principios de la década de los años 1990. En la actualidad, existe variedad de lenguajes de programación que soportan la orientación a objetos.
Conceptos Fundamentales
La programación orientada a objetos es una forma de programar que trata de encontrar una solución a estos problemas. Introduce nuevos conceptos, que superan y amplían conceptos antiguos ya conocidos. Entre ellos destacan los siguientes:
- Clase: definiciones de las propiedades y comportamiento de un tipo de objeto concreto. La instanciación es la lectura de estas definiciones y la creación de un objeto a partir de ellas.
- Herencia: (por ejemplo, herencia de la clase C a la clase D) Es la facilidad mediante la cual la clase D hereda en ella cada uno de los atributos y operaciones de C, como si esos atributos y operaciones hubiesen sido definidos por la misma D. Por lo tanto, puede usar los mismos métodos y variables publicas declaradas en C. Los componentes registrados como "privados" (private) también se heredan, pero como no pertenecen a la clase, se mantienen escondidos al programador y sólo pueden ser accedidos a través de otros métodos públicos. Esto es así para mantener hegemónico el ideal de OOP.
- Objeto: entidad provista de un conjunto de propiedades o atributos (datos) y de comportamiento o funcionalidad (métodos) los mismos que consecuentemente reaccionan a eventos. Se corresponde con los objetos reales del mundo que nos rodea, o a objetos internos del sistema (del programa). Es una instancia a una clase.
- Método: Algoritmo asociado a un objeto (o a una clase de objetos), cuya ejecución se desencadena tras la recepción de un "mensaje". Desde el punto de vista del comportamiento, es lo que el objeto puede hacer. Un método puede producir un cambio en las propiedades del objeto, o la generación de un "evento" con un nuevo mensaje para otro objeto del sistema.
- Evento: Es un suceso en el sistema (tal como una interacción del usuario con la máquina, o un mensaje enviado por un objeto). El sistema maneja el evento enviando el mensaje adecuado al objeto pertinente. También se puede definir como evento, a la reacción que puede desencadenar un objeto, es decir la acción que genera.
- Mensaje: una comunicación dirigida a un objeto, que le ordena que ejecute uno de sus métodos con ciertos parámetros asociados al evento que lo generó.
- Propiedad o atributo: contenedor de un tipo de datos asociados a un objeto (o a una clase de objetos), que hace los datos visibles desde fuera del objeto y esto se define como sus características predeterminadas, y cuyo valor puede ser alterado por la ejecución de algún método.
- Estado interno: es una variable que se declara privada, que puede ser únicamente accedida y alterada por un método del objeto, y que se utiliza para indicar distintas situaciones posibles para el objeto (o clase de objetos). No es visible al programador que maneja una instancia de la clase.
- Componentes de un objeto: atributos, identidad, relaciones y métodos.
- Identificación de un objeto: un objeto se representa por medio de una tabla o entidad que esté compuesta por sus atributos y funciones correspondientes.
En comparación con un lenguaje imperativo, una "variable", no es más que un contenedor interno del atributo del objeto o de un estado interno, así como la "función" es un procedimiento interno del método del objeto.
PATRONES DE DESARROLLO
HTML
 Siglas de HyperText Markup Language (Lenguaje de Marcado de Hipertexto), es el lenguaje de marcado predominante para la elaboración de páginas web. Es usado para describir la estructura y el contenido en forma de texto, así como para complementar el texto con objetos tales como imágenes. HTML se escribe en forma de "etiquetas", rodeadas por corchetes angulares (<,>). HTML también puede describir, hasta un cierto punto, la apariencia de un documento, y puede incluir un script (por ejemplo Javascript), el cual puede afectar el comportamiento de navegadores web y otros procesadores de HTML.
Siglas de HyperText Markup Language (Lenguaje de Marcado de Hipertexto), es el lenguaje de marcado predominante para la elaboración de páginas web. Es usado para describir la estructura y el contenido en forma de texto, así como para complementar el texto con objetos tales como imágenes. HTML se escribe en forma de "etiquetas", rodeadas por corchetes angulares (<,>). HTML también puede describir, hasta un cierto punto, la apariencia de un documento, y puede incluir un script (por ejemplo Javascript), el cual puede afectar el comportamiento de navegadores web y otros procesadores de HTML. HTML también es usado para referirse al contenido del tipo de MIME text/html o todavía más ampliamente como un término genérico para el HTML, ya sea en forma descendida del XML (como XHTML 1.0 y posteriores) o en forma descendida directamente de SGML (como HTML 4.01 y anteriores).
CSS
 Es un lenguaje de hojas de estilo usado para describir la semántica de la presentación (la apariencia y formato) de un documento escrito en un lenguaje de marcas .Su aplicación más común es el estilo de las páginas web escritas en HTML y XHTML , pero el lenguaje también se puede aplicar a cualquier tipo de XML documento, incluyendo SVG y XUL .
Es un lenguaje de hojas de estilo usado para describir la semántica de la presentación (la apariencia y formato) de un documento escrito en un lenguaje de marcas .Su aplicación más común es el estilo de las páginas web escritas en HTML y XHTML , pero el lenguaje también se puede aplicar a cualquier tipo de XML documento, incluyendo SVG y XUL .CONTROLES DE VERSIONES
Una versión, revisión o edición de un producto, es el estado en el que se encuentra dicho producto en un momento dado de su desarrollo o modificación. Se llama control de versiones a la gestión de los diversos cambios que se realizan sobre los elementos de algún producto o una configuración del mismo. Los sistemas de control de versiones facilitan la administración de las distintas versiones de cada producto desarrollado, así como las posibles especializaciones realizadas (por ejemplo, para algún cliente específico).
El control de versiones se realiza principalmente en la industria informática para controlar las distintas versiones del código fuente. Sin embargo, los mismos conceptos son aplicables a otros ámbitos como documentos, imágenes, sitios web, etcétera.
Aunque un sistema de control de versiones puede realizarse de forma manual, es muy aconsejable disponer de herramientas que faciliten esta gestión (CVS, Subversion, SourceSafe, ClearCase, Darcs, Bazaar, Plastic SCM, Git, Mercurial, etc.).
Características
Un sistema de control de versiones debe proporcionar:
- Mecanismo de almacenaje de los elementos que deba gestionar (ej. archivos de texto, imágenes, documentación...)
- Posibilidad de realizar cambios sobre los elementos almacenados (ej. modificaciones parciales, añadir, borrar, renombrar o mover elementos)
- Registro histórico de las acciones realizadas con cada elemento o conjunto de elementos (normalmente pudiendo volver o extraer un estado anterior del producto)
Aunque no es estrictamente necesario, suele ser muy útil la generación de informes con los cambios introducidos entre dos versiones, informes de estado, marcado con nombre identificativo de la versión de un conjunto de ficheros, etcétera.
LINUX
 Es uno de los términos empleados para referirse a la combinación del núcleo o kernel libre similar a Unix denominado Linux, que es usado con herramientas de sistema GNU. Su desarrollo es uno de los ejemplos más prominentes de software libre; todo su código fuente puede ser utilizado, modificado y redistribuido libremente por cualquiera bajo los términos de la GPL (Licencia Pública General de GNU) y otra serie de licencias libres.
Es uno de los términos empleados para referirse a la combinación del núcleo o kernel libre similar a Unix denominado Linux, que es usado con herramientas de sistema GNU. Su desarrollo es uno de los ejemplos más prominentes de software libre; todo su código fuente puede ser utilizado, modificado y redistribuido libremente por cualquiera bajo los términos de la GPL (Licencia Pública General de GNU) y otra serie de licencias libres. El proyecto GNU, que fue iniciado en 1983 por Richard Stallman, tiene como objetivo el desarrollo de un sistema operativo Unix completo y compuesto enteramente de software libre. La historia del núcleo Linux está fuertemente vinculada a la del proyecto GNU. En 1991 Linus Torvalds empezó a trabajar en un reemplazo no comercial para MINIX que más adelante acabaría siendo Linux.
El proyecto GNU, que fue iniciado en 1983 por Richard Stallman, tiene como objetivo el desarrollo de un sistema operativo Unix completo y compuesto enteramente de software libre. La historia del núcleo Linux está fuertemente vinculada a la del proyecto GNU. En 1991 Linus Torvalds empezó a trabajar en un reemplazo no comercial para MINIX que más adelante acabaría siendo Linux.Cuando Torvalds liberó la primera versión de Linux, el proyecto GNU ya había producido varias de las herramientas fundamentales para el manejo del sistema operativo, incluyendo un intérprete de comandos, una biblioteca C y un compilador, pero como el proyecto contaba con una infraestructura para crear su propio sistema operativo, el llamado Hurd, y este aún no era lo suficiente maduro para usarse, comenzaron a usar a Linux a modo de continuar desarrollando el proyecto GNU, siguiendo la tradicional filosofía de mantener cooperatividad entre desarrolladores. El día en que se estime que Hurd es suficiente maduro y estable, será llamado a reemplazar a Linux.
Entonces, el núcleo creado por Linus Torvalds, quien se encontraba por entonces estudiando en la Universidad de Helsinki, llenó el "espacio" final que había en el sistema operativo de GNU.
KERNEL
 (de la raíz germánica Kern) es un software que actúa de sistema operativo.Es el principal responsable de facilitar a los distintos programas acceso seguro al hardware de la computadora o en forma más básica, es el encargado de gestionar recursos, a través de servicios de llamada al sistema. Como hay muchos programas y el acceso al hardware es limitado, también se encarga de decidir qué programa podrá hacer uso de un dispositivo de hardware y durante cuánto tiempo, lo que se conoce como multiplexado. Acceder al hardware directamente puede ser realmente complejo, por lo que los núcleos suelen implementar una serie de abstracciones del hardware. Esto permite esconder la complejidad, y proporciona una interfaz limpia y uniforme al hardware subyacente, lo que facilita su uso al programador.
(de la raíz germánica Kern) es un software que actúa de sistema operativo.Es el principal responsable de facilitar a los distintos programas acceso seguro al hardware de la computadora o en forma más básica, es el encargado de gestionar recursos, a través de servicios de llamada al sistema. Como hay muchos programas y el acceso al hardware es limitado, también se encarga de decidir qué programa podrá hacer uso de un dispositivo de hardware y durante cuánto tiempo, lo que se conoce como multiplexado. Acceder al hardware directamente puede ser realmente complejo, por lo que los núcleos suelen implementar una serie de abstracciones del hardware. Esto permite esconder la complejidad, y proporciona una interfaz limpia y uniforme al hardware subyacente, lo que facilita su uso al programador.DEMONIO
Es un script, un proceso que normalmente esta cargado en memoria esperando una señal para ser ejecutado.
Que estén cargados en memoria no significan que ocupan CPU por lo que por muchos que tengamos, podremos trabajar sin problemas con el ordenador.
Los daemons son procesos que se ejecutan en modo background.
Normalmente cada daemon tiene asociado un shell script situado en la carpeta /etc/init.d/ que nos permite iniciarlo, pararlo o ver su estado.
Esta carpeta puede variar dependiendo de la distribución, ya que por ejemplo en red hat están en /etc/rc.d/
Para arrancar, lanzar un daemon tenemos que utilizar el comando start.
Para pararlo tendremos que utilizar el comando stop.
El comando restart reinicia el daemon haciendo que se vuelvan a leer los archivos de configuración del mismo.
Para ejecutar un daemon debemos llamarlo con su ruta completa y pasarle el parámetro que nos interese.
Que estén cargados en memoria no significan que ocupan CPU por lo que por muchos que tengamos, podremos trabajar sin problemas con el ordenador.
Los daemons son procesos que se ejecutan en modo background.
Normalmente cada daemon tiene asociado un shell script situado en la carpeta /etc/init.d/ que nos permite iniciarlo, pararlo o ver su estado.
Esta carpeta puede variar dependiendo de la distribución, ya que por ejemplo en red hat están en /etc/rc.d/
Para arrancar, lanzar un daemon tenemos que utilizar el comando start.
Para pararlo tendremos que utilizar el comando stop.
El comando restart reinicia el daemon haciendo que se vuelvan a leer los archivos de configuración del mismo.
Para ejecutar un daemon debemos llamarlo con su ruta completa y pasarle el parámetro que nos interese.
NOMBRE DE DISTRIBUCIONES
Además del núcleo Linux, las distribuciones incluyen habitualmente las bibliotecas y herramientas del proyecto GNU y el sistema de ventanas X Window System. Dependiendo del tipo de usuarios a los que la distribución esté dirigida se incluye también otro tipo de software como procesadores de texto, hoja de cálculo, reproductores multimedia, herramientas administrativas, etcétera. En el caso de incluir herramientas del proyecto GNU, también se utiliza el término distribución GNU/Linux.
Existen distribuciones que están soportadas comercialmente, como Fedora (Red Hat), openSUSE (Novell), Ubuntu (Canonical Ltd.), Mandriva, y distribuciones mantenidas por la comunidad como Debian y Gentoo. Aunque hay otras distribuciones que no están relacionadas con alguna empresa o comunidad, como es el caso de Slackware.

{kind=link}
GNU
El proyecto GNU fue iniciado por Richard Stallman con el objetivo de crear un sistema operativo completamente libre: el sistema GNU.
 El 27 de septiembre de 1983 se anunció públicamente el proyecto por primera vez en el grupo de noticias net.unix-wizards. Al anuncio original, siguieron otros ensayos escritos por Richard Stallman como el "Manifiesto GNU", que establecieron sus motivaciones para realizar el proyecto GNU, entre las que destaca "volver al espíritu de cooperación que prevaleció en los tiempos iniciales de la comunidad de usuarios de computadoras".
El 27 de septiembre de 1983 se anunció públicamente el proyecto por primera vez en el grupo de noticias net.unix-wizards. Al anuncio original, siguieron otros ensayos escritos por Richard Stallman como el "Manifiesto GNU", que establecieron sus motivaciones para realizar el proyecto GNU, entre las que destaca "volver al espíritu de cooperación que prevaleció en los tiempos iniciales de la comunidad de usuarios de computadoras".Etimología
 GNU es un acrónimo recursivo que significa GNU No es Unix (GNU is Not Unix). Puesto que en inglés "gnu" (en español "ñu") se pronuncia igual que "new", Richard Stallman recomienda pronunciarlo "guh-noo". En español, se recomienda pronunciarlo ñu como el antílope africano o fonéticamente; por ello, el término mayoritariamente se deletrea (G-N-U) para su mejor comprensión. En sus charlas Richard Stallman finalmente dice siempre «Se puede pronunciar de cualquier forma, la única pronunciación errónea es decirle 'linux'».
GNU es un acrónimo recursivo que significa GNU No es Unix (GNU is Not Unix). Puesto que en inglés "gnu" (en español "ñu") se pronuncia igual que "new", Richard Stallman recomienda pronunciarlo "guh-noo". En español, se recomienda pronunciarlo ñu como el antílope africano o fonéticamente; por ello, el término mayoritariamente se deletrea (G-N-U) para su mejor comprensión. En sus charlas Richard Stallman finalmente dice siempre «Se puede pronunciar de cualquier forma, la única pronunciación errónea es decirle 'linux'».GPL
La Licencia Pública General de GNU o más conocida por su nombre en inglés GNU General Public License o simplemente sus siglas del inglés GNU GPL, es una licencia creada por la Free Software Foundation en 1989 (la primera versión), y está orientada principalmente a proteger la libre distribución, modificación y uso de software. Su propósito es declarar que el software cubierto por esta licencia es software libre y protegerlo de intentos de apropiación que restrinjan esas libertades a los usuarios.
Existen varias licencias "hermanas" de la GPL, como la licencia de documentación libre de GNU (GFDL), la Open Audio License, para trabajos musicales, etcétera, y otras menos restrictivas, como la MGPL, o la LGPL (Lesser General Publical License, antes Library General Publical License), que permiten el enlace dinámico de aplicaciones libres a aplicaciones no libres.
Validez legal
La licencia GPL, al ser un documento que cede ciertos derechos al usuario, asume la forma de un contrato, por lo que usualmente se la denomina contrato de licencia o acuerdo de licencia.En los países de tradición anglosajona existe una distinción doctrinal entre licencias y contratos, pero esto no ocurre en los países de tradición civil o continental. Como contrato, la GPL debe cumplir los requisitos legales de formación contractual en cada jurisdicción.
La licencia ha sido reconocida por juzgados en Alemania, particularmente en el caso de una sentencia en un tribunal de Múnich,lo que indica positivamente su validez en jurisdicciones de derecho civil.
CONSOLA
Se trata de uno o varios terminales conectados al ordenador central, que permiten monitorizar su funcionamiento, controlar las operaciones que realiza, regular las aplicaciones que deben ejecutarse, etc.


SAMBA
Samba es un software libre, reimplementación del protocolo de red Microsoft Windows Network (antes llamado SMB/CIFS), realizado bajo licencia GNU GPL. El nombre "samba", proviene de la inserción de dos vocales en el nombre original del protocolo "SMB".
Para la versión 3, Samba, además proveer servicios de archivo e impresión, también puede integrarse al dominio Windows Server. También puede ser parte de dominio Active Directory.
Samba permite que un servidor no-Windows se comunique con los mismos protocolos de red que los productos para Windows.
Samba se ejecuta en la mayoría de los sistemas Unix y basados en Unix, como Linux, Solaris y los BSD, incluyendo el Mac OS X Server de Apple.
ESTRUCTURA DE DIRECTORIOS Y PARA QUE SIRVEN
 Estructuran la información guardada en una unidad de almacenamiento (normalmente un disco duro de una computadora), que luego será representada ya sea textual o gráficamente utilizando un gestor de archivos. La mayoría de los sistemas operativos manejan su propio sistema de archivos.
Estructuran la información guardada en una unidad de almacenamiento (normalmente un disco duro de una computadora), que luego será representada ya sea textual o gráficamente utilizando un gestor de archivos. La mayoría de los sistemas operativos manejan su propio sistema de archivos. Lo habitual es utilizar dispositivos de almacenamiento de datos que permiten el acceso a los datos como una cadena de bloques de un mismo tamaño, a veces llamados sectores, usualmente de 512 bytes de longitud. El software del sistema de archivos es responsable de la organización de estos sectores en archivos y directorios y mantiene un registro de qué sectores pertenecen a qué archivos y cuáles no han sido utilizados. En la práctica, un sistema de archivos también puede ser utilizado para acceder a datos generados dinámicamente, como los recibidos a través de una conexión de red (sin la intervención de un dispositivo de almacenamiento).
Ejemplo de 'ruta' en un sistema Unix
Así, por ejemplo, en un sistema tipo Unix como GNU/Linux, la ruta para la canción llamada "canción.ogg" del usuario "pedro" sería algo como:
/home/pedro/musica/cancion.oggdonde:
- '/' representa el directorio raíz donde está montado todo el sistema de archivos.
- 'home/pedro/musica/' es la ruta del archivo.
- 'canción.ogg' es el nombre del archivo.
que se establece como único.
Ejemplo de 'ruta' en un sistema Windows
Un ejemplo análogo en un sistema de archivos de Windows (específicamente en Windows XP) se vería como:
C:\Documents and Settings\pedro\Mis Documentos\Mi Música\canción.oggdonde:
- 'C:' es la unidad de almacenamiento en la que se encuentra el archivo.
- '\Documents and Settings\pedro\Mis Documentos\Mi Música\' es la ruta del archivo.
- 'canción' es el nombre del archivo.
- '.ogg' es la extensión del archivo, este elemento, parte del nombre, es especialmente relevante en los sistemas Windows, ya que sirve para identificar qué aplicación está asociada con el archivo en cuestión, es decir, con qué programa se puede editar o reproducir el archivo.
NOMBRE DE ADMINISTRADOR DE ARCHIVOS El Administrador de archivos es el área central de almacenamiento de los archivos que constituyen un curso de WebCT. Esta área se encuentra en un servidor remoto, que es un ordenador conectado en red donde se ejecuta el software del servidor de WebCT. Este servidor puede estar situado en la red de su institución o en un proveedor de servicios de Internet, es decir, puede encontrarse geográficamente distante o en la puerta de al lado. Sin embargo, es importante recordar que tanto el profesor como los alumnos interactúan con este servidor remoto cada vez que acceden a un curso de WebCT. El software que utiliza para acceder a los cursos de WebCT desde su ordenador es el navegador de Netscape o el de Internet Explorer.
Un curso de WebCT está formado por archivos HTML, de texto y gráficos que utilizan las distintas herramientas de WebCT. Generalmente, los archivos del curso se preparan en un ordenador personal para luego transferirlos al Administrador de archivos, que se encuentra en el servidor remoto de WebCT. Una vez añadidos al Administrador de archivos, los archivos se pueden enlazar con las distintas áreas del curso. En el Administrador de archivos, los archivos de los cursos de WebCT están estructurados y guardados en carpetas y subcarpetas. Para ver los archivos de una carpeta, sólo tiene que hacer clic en su nombre.
Utilice el Administrador de archivos para realizar las siguientes operaciones:
- Navegar por los archivos e imágenes incorporados de WebCT
- Cargar archivos al servidor de WebCT
- Descargar archivos del servidor de WebCT a su ordenador
- Comprimir y descomprimir archivos en el servidor de WebCT.
- Copiar, borrar, cambiar de nombre y mover archivos
- Crear carpetas nuevas
- Editar archivos del servidor de WebCT
La forma de transferir archivos a WebCT presenta algunas diferencias con la que se emplea en los sistemas operativos Windows y Macintosh, ya que no es posible "arrastrar y soltar" los archivos y carpetas a WebCT, sino cargarlos desde su ordenador. Consulte Cargar archivos si desea información sobre cómo realizar esta operación.
Fat32, NTFS, Ext
FAT32: Fue la respuesta para superar el límite de tamaño de FAT16 al mismo tiempo que se mantenía la compatibilidad con MS-DOS en modo real. Microsoft decidió implementar una nueva generación de FATcluster de 32 bits (aunque sólo 28 de esos bits se utilizaban realmente). utilizando direcciones de
En teoría, esto debería permitir aproximadamente 268.435.538 clusters, arrojando tamaños de almacenamiento cercanos a los ocho terabytes. Sin embargo, debido a limitaciones en la utilidad ScanDisk de Microsoft, no se permite que FAT32 crezca más allá de 4.177.920 clusters por partición (es decir, unos 124 gigabytes). Posteriormente, Windows 2000 y XP situaron el límite de FAT32 en los 32 gigabytes. Microsoft afirma que es una decisión de diseño, sin embargo, es capaz de leer particiones mayores creadas por otros medios.
FAT32 apareció por primera vez en Windows 95 OSR2. Era necesario reformatear para usar las ventajas de FAT32. Curiosamente, DriveSpace 3 (incluido con Windows 95 y 98) no lo soportaba. Windows 98 incorporó una herramienta para convertir de FAT16 a FAT32 sin pérdida de los datos. Este soporte no estuvo disponible en la línea empresarial hasta Windows 2000.
El tamaño máximo de un archivo en FAT32 es 4 gigabytes (232−1 bytes), lo que resulta engorroso para aplicaciones de captura y edición de video, ya que los archivos generados por éstas superan fácilmente ese límite.
NTFS: (NT File System) es un sistema de archivos de Windows NT incluido en las versiones de Windows 2000, Windows XP, Windows Server 2003, Windows Server 2008, Windows Vista y Windows 7. Está basado en el sistema de archivos HPFS de IBM/Microsoft usado en el sistema operativo OS/2, y también tiene ciertas influencias del formato de archivos HFS diseñado por Apple.
NTFS permite definir el tamaño del clúster, a partir de 512 bytes (tamaño mínimo de un sector) de forma independiente al tamaño de la partición.
Es un sistema adecuado para las particiones de gran tamaño requeridas en estaciones de trabajo de alto rendimiento y servidores. Puede manejar volúmenes de, teóricamente, hasta 264–1 clústeres. En la práctica, el máximo volumen NTFS soportado es de 232–1 clústeres (aproximadamente 16 Terabytes usando clústeres de 4KB).
Los inconvenientes que plantea son:
- Necesita para sí mismo una buena cantidad de espacio en disco duro, por lo que no es recomendable su uso en discos con menos de 400 MB libres.
EXT:(third extended filesystem o "tercer sistema de archivos extendido") es un sistema de archivos con registro por diario (journaling). Es el sistema de archivo más usado en distribuciones Linux, aunque en la actualidad está siendo remplazado por su sucesor, ext4.
La principal diferencia con ext2 es el registro por diario. Un sistema de archivos ext3 puede ser montado y usado como un sistema de archivos ext2. Otra diferencia importante es que ext3 utiliza un árbol binario balanceado (árbol AVL) e incorpora el asignador de bloques de disco Orlov.
UNIDAD PRIMARIA, SECUNDARIA, LOGICA
El formato o sistema de archivos de las particiones (p. ej. NTFS) no debe ser confundido con el tipo de partición (p. ej. partición primaria), ya que en realidad no tienen directamente mucho que ver. Independientemente del sistema de archivos de una partición (FAT, ext3, NTFS, etc.), existen 3 tipos diferentes de particiones:
- Partición primaria: Son las divisiones crudas o primarias del disco, solo puede haber 4 de éstas o 3 primarias y una extendida. Depende de una tabla de particiones. Un disco físico completamente formateado consiste, en realidad, de una partición primaria que ocupa todo el espacio del disco y posee un sistema de archivos. A este tipo de particiones, prácticamente cualquier sistema operativo puede detectarlas y asignarles una unidad, siempre y cuando el sistema operativo reconozca su formato (sistema de archivos).
- Partición extendida: Tambien conocida como partición secundaria es otro tipo de partición que actúa como una partición primaria; sirve para contener infinidad de unidades lógicas en su interior. Fue ideada para romper la limitación de 4 particiones primarias en un solo disco físico. Solo puede existir una partición de este tipo por disco, y solo sirve para contener particiones lógicas. Por lo tanto, es el único tipo de partición que no soporta un sistema de archivos directamente.
- Partición lógica: Ocupa una porción de la partición extendida o la totalidad de la misma, la cual se ha formateado con un tipo específico de sistema de archivos (FAT32, NTFS, ext2,...) y se le ha asignado una unidad, así el sistema operativo reconoce las particiones lógicas o su sistema de archivos. Puede haber un máximo de 23 particiones lógicas en una partición extendida. Linux impone un maximo de 15, incluyendo las 4 primarias, en discos SCSI y en discos IDE 63.
Particiones primarias
En los equipos PC, originales de IBM, estas particiones tradicionalmente usan una estructura llamada Tabla de particiones, ubicada al final del registro de arranque maestro (MBR, Master Boot Record). Esta tabla, que no puede contener más de 4 registros de particiones (también llamados partition descriptors), especifica para cada una su principio, final y tamaño en los diferentes modos de direccionamiento, así también como un solo número, llamado partition type, y un marcador que indica si la partición está activa o no (sólo puede haber una partición activa a la vez). El marcador se usa durante el arranque; después de que el BIOS cargue el registro de arranque maestro en la memoria y lo ejecute, el MBR de DOS comprueba la tabla de partición a su final y localiza la partición activa. Entonces carga el sector de arranque de esta partición en memoria y la ejecuta. A diferencia del registro de arranque maestro, generalmente independiente del sistema operativo, el sector de arranque está instalado junto con el sistema operativo y sabe cómo cargar el sistema ubicado en ese disco en particular.
Notar que mientras la presencia de un marcador activo se estandariza, no se utiliza en todos los gestores de arranque. Por ejemplo, los gestores LILO, GRUB (muy comunes en el sistema Linux) y XOSL no buscan en la tabla de particiónes del MBR la partición activa; simplemente cargan una segunda etapa (que puede ser contenida en el resto del cilindro 0 ó en el sistema de archivos). Después de cargar la segunda etapa se puede cargar el sector de arranque de cualquiera de las particiones del disco (permitiendo al usuario seleccionar la partición), o si el gestor conoce cómo localizar el kernel (núcleo) del sistema operativo en una de las particiones (puede permitir al usuario especificar opciones de kernel adicionales para propósitos de recuperación).
Particiones extendidas y lógicas
Cualquier versión del DOS puede leer sólo una partición FAT primaria en el disco duro. Esto unido al deterioro de la FAT con el uso y al aumento de tamaño de los discos movió a Microsoft a crear un esquema mejorado relativamente simple: una de las entradas de la tabla de partición principal pasó a llamarse partición extendida y recibió un número de tipo de partición especial (0x05). El campo inicio de partición tiene la ubicación del primer descriptor de la partición extendida, que a su vez tiene un campo similar con la ubicación de la siguiente; así se crea una lista enlazada de descriptores de partición. Los demás campos de una partición extendida son indefinidos, no tienen espacio asignado y no pueden usarse para almacenar datos. Las particiones iniciales de los elementos de la lista enlazada son las llamadas unidades lógicas; son espacios asignados y pueden almacenar datos. Los sistemas operativos antiguos ignoraban las particiones extendidas con número de tipo 0x05, y la compatibilidad se mantenía. Este esquema reemplaza al antiguo ya que todas las particiones de un disco duro se pueden poner dentro de una sola partición extendida. Por alguna razón, Microsoft no actualizó su sistema operativo DOS para arrancar desde una partición extendida, debido a que la necesidad para particiones primarias se preservaron. Por encima de éstas todavía se habría permitido una partición FAT primaria por unidad, significando todas las otras particiones FAT primarias deben tener sus números de tipo de partición prior cambiando al arranque DOS, para que ésta sea capaz de proceder. Esta técnica, usada por varios administradores de arranque populares, se llama ocultación de la partición. Sin embargo hay que tener en cuenta una quinta partición que se puede comprimir pero no es muy recomendable.
UBUNTU 10.10
 Es una distribución Linux basada en Debian GNU/Linux que proporciona un sistema operativo actualizado y estable para el usuario medio, con un fuerte enfoque en la facilidad de uso y de instalación del sistema. Al igual que otras distribuciones se compone de múltiples paquetes de software normalmente distribuidos bajo una licencia libre o de código abierto. Estadísticas web sugieren que el porcentaje de mercado de Ubuntu dentro de las distribuciones Linux es de aproximadamente 50%, y con una tendencia a subir como servidor web.
Es una distribución Linux basada en Debian GNU/Linux que proporciona un sistema operativo actualizado y estable para el usuario medio, con un fuerte enfoque en la facilidad de uso y de instalación del sistema. Al igual que otras distribuciones se compone de múltiples paquetes de software normalmente distribuidos bajo una licencia libre o de código abierto. Estadísticas web sugieren que el porcentaje de mercado de Ubuntu dentro de las distribuciones Linux es de aproximadamente 50%, y con una tendencia a subir como servidor web.El Software Incluido
 Posee una gran colección de aplicaciones para la configuración de todo el sistema, valiéndose principalmente de interfaces gráficas. El entorno de escritorio predeterminado de Ubuntu es GNOME y se sincroniza con sus liberaciones. Existen otras dos versiones oficiales de la distribución, una con el entorno KDE, llamada Kubuntu, y otra con el entorno Xfce, llamada Xubuntu; existen otros escritorios disponibles, que pueden ser instalados en cualquier sistema Ubuntu independientemente del entorno de escritorio instalado por defecto.
Posee una gran colección de aplicaciones para la configuración de todo el sistema, valiéndose principalmente de interfaces gráficas. El entorno de escritorio predeterminado de Ubuntu es GNOME y se sincroniza con sus liberaciones. Existen otras dos versiones oficiales de la distribución, una con el entorno KDE, llamada Kubuntu, y otra con el entorno Xfce, llamada Xubuntu; existen otros escritorios disponibles, que pueden ser instalados en cualquier sistema Ubuntu independientemente del entorno de escritorio instalado por defecto.- Aplicaciones de Ubuntu: Ubuntu es conocido por su facilidad de uso y las aplicaciones orientadas al usuario final. Las principales aplicaciones que trae Ubuntu son: navegador web Mozilla Firefox, cliente de mensajería instantánea Empathy, cliente de redes sociales Gwibber, cliente para enviar y recibir correo Evolution, reproductor multimedia Totem, reproductor de música Rhythmbox, editor de vídeos PiTiVi, editor de imágenes Shotwell, cliente y gestor de BitTorrents Transmission, grabador de discos Brasero, suite ofimática Open Office, y el instalador central para buscar e instalar aplicaciones Centro de software de Ubuntu.
- Seguridad y accesibilidad: El sistema incluye funciones avanzadas de seguridad y entre sus políticas se encuentra el no activar, de forma predeterminada, procesos latentes al momento de instalarse. Por eso mismo, no hay un cortafuegos predeterminado, ya que no existen servicios que puedan atentar a la seguridad del sistema. Para labores o tareas administrativas en la línea de comandos incluye una herramienta llamada sudo (de las siglas en inglés de SuperUser do), con la que se evita el uso del usuario administrador. Posee accesibilidad e internacionalización, de modo que el sistema esté disponible para tanta gente como sea posible. Desde la versión 5.04, se utiliza UTF-8 como codificación de caracteres predeterminado.

No sólo se relaciona con Debian por el uso del mismo formato de paquetes deb. También tiene uniones muy fuertes con esa comunidad, contribuyendo con cualquier cambio directa e inmediatamente, y no sólo anunciándolos. Esto sucede en los tiempos de lanzamiento. Muchos de los desarrolladores de Ubuntu son también responsables de los paquetes importantes dentro de la distribución Debian.
Para centrarse en solucionar rápidamente los bugs, conflictos de paquetes, etc. se decidió eliminar ciertos paquetes del componente main, ya que no son populares o simplemente se escogieron de forma arbitraria por gusto o sus bases de apoyo al software libre. Por tales motivos inicialmente KDE no se encontraba con más soporte de lo que entregaban los mantenedores de Debian en sus repositorios, razón por la que se sumó la comunidad de KDE creando la distribución Linux Kubuntu.
FORMAS DE INSTALACION
CD oficiales
 Todos los lanzamientos de Ubuntu se proporcionan sin costo alguno. Los CD de la distribución se envían de forma gratuita a cualquier persona que los solicite mediante el servicio ShipIt(una excepción fue la versión 6.10, la cual no se llegó a distribuir de forma gratuita en CD).
Todos los lanzamientos de Ubuntu se proporcionan sin costo alguno. Los CD de la distribución se envían de forma gratuita a cualquier persona que los solicite mediante el servicio ShipIt(una excepción fue la versión 6.10, la cual no se llegó a distribuir de forma gratuita en CD).También es posible descargar las imágenes ISO de los discos por descarga directa o a través de redes P2P y archivos torrents, reduciendo así la carga en los servidores.
Ubuntu está disponible, de forma opcional, en DVD para minimizar su dependencia de Internet.
- Instalación de escritorio (desktop): es el medio más usado por los usuarios ya que, al ser un LiveCD, permite probar Ubuntu sin hacer ningún cambio en el equipo y agrega una opción para instalarlo permanentemente más tarde.
- Instalación en servidores (server): permite instalar Ubuntu permanentemente en una computadora usada como servidor. No instala una interfaz gráfica de usuario por defecto.
- Instalación alternativa (alternate): facilita la creación de sistemas OEM pre-configurados, configuración automatizada de despliegues, actualización desde instalaciones anteriores sin acceso a la red, gestión de particiones LVM o RAID y la instalación en equipos con poca memoria RAM gracias al uso de un instalador a modo de texto.
Otras instalaciones
- Wubi: un instalador libre y oficial de Ubuntu para sistemas operativos Windows cuyo objetivo es el de permitir que usuarios de ese sistema, no acostumbrados a Linux, puedan probar Ubuntu sin el riesgo de perder información durante un formateo o la modificación de particiones. El programa viene de serie en el LiveCD de Ubuntu, aunque es posible descargarlo de la página oficial.
- LiveUSB: una herramienta que viene de serie y que permite la creación de un LiveUSB de la distribución, de modo que se pueda cargar el sistema desde una memoria US permitiendo guardar datos y configuraciones en el mismo, pero con la limitación de que sólo funciona en una computadora cuya placa base soporte el arranque desde un medio USB.
- LiveCD/DVD personalizado: existen herramientas como Reconstructor, UCK o remastersys que permiten a cualquiera crear fácilmente un LiveCD/DVD personalizado de una instalación existente de Ubuntu.
- CD de instalación mediante red: se trata de una imagen ISO de apenas unos 10MB que contiene los paquetes necesarios para descargar el sistema base desde los repositorios oficiales de Ubuntu y posteriormente elegir el escritorio deseado.
REQUISITOS MINIMOS

Los requisitos mínimos «recomendados», teniendo en cuenta los efectos de escritorio, deberían permitir ejecutar una instalación de Ubuntu.
- Procesador x86 a 1 GHz.
- Memoria RAM: 1 GB.
- Disco Duro: 15 GB (swap incluida).
- Tarjeta gráfica VGA y monitor capaz de soportar una resolución de 1024x768.
- Lector de CD-ROM o puerto USB
- Conexión a Internet puede ser útil.
Los efectos de escritorio, proporcionados por Compiz, se activan por defecto en las siguientes tarjetas gráficas:
- Intel (i915 o superior, excepto GMA 500, nombre en clave «Poulsbo»)
- NVidia (con su controlador propietario)
- ATI (a partir del modelo Radeon HD 2000 puede ser necesario el controlador propietario)
Si se dispone de una computadora con un procesador de 64 bits (x86-64), y especialmente si dispone de más de 3 GB de RAM, se recomienda utilizar la versión de Ubuntu para sistemas de 64 bits.
Suscribirse a:
Comentarios (Atom)